In this article, we explore what tokens are and how they are calculated. Furthermore, we provide a concrete example of their use and offer tips for efficient token saving.
- Definition of Tokens
- How Tokens are Calculated
- An Example of Tokens
- A Comparison Between Word and Subword Tokenization
- Efficient Use of Tokens
Definition of Tokens
Tokens are a central component in the text processing of machine learning models like OpenAI’s ChatGPT, forming the basis for understanding and interpreting text data. These elements, also referred to as tokens, are the smallest units that such models can process.
In its simplest form, a token can represent a single word, a punctuation mark, or a space. However, more complex models like ChatGPT extend this concept and can define tokens as parts of a word or even multiple words. This approach is known as subword tokenization.
How Tokens are Calculated
When processing a text, it is first broken down into a series of tokens. This process is called tokenization. The model then uses the representative numerical values of these tokens to analyze and predict the text.
An important aspect is the limitation of the number of tokens that a model can process. For example, with GPT-3.5 Turbo, this limit is 4,096 tokens, and with GPT-4, it is 8,192 tokens. This limitation applies to both input and output texts and is also referred to as the context window. The number of tokens allowed in a chat model like ChatGPT depends not only on the technical limitations of the model itself but can also be set by the operator of the chat or the specific application.
An Example of Tokens
A sentence like “ChatGPT is a language model from OpenAI” would be broken down into individual tokens. In a simple word tokenization, this sentence might be broken down into the following tokens:
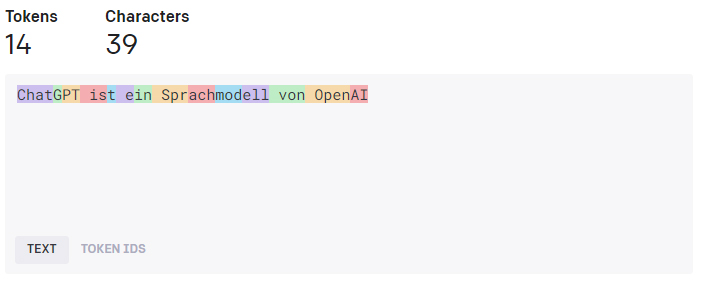
However, in subword tokenization, the same sentence could be broken down into more or fewer tokens, depending on the specific tokenization logic of the model.
A Comparison Between Word and Subword Tokenization
Let’s say we have a text of 1,000 words. In a simple word tokenization, we would also have 1,000 tokens. However, in subword tokenization, the number of tokens could vary. A word like “configuration,” for example, could be broken down into several tokens such as “Confi,” “gura,” “tion.” Similarly, a punctuation mark or a space could also be counted as a separate token. This means that the number of tokens could be higher than the number of words in the text.
Efficient Use of Tokens
In general, the less text there is in both the question and the
answer, the fewer tokens are consumed. This is an important aspect to keep in mind when using models like ChatGPT to maximize efficiency and optimize token usage.
Efficient Text Input: Try to make your input as concise and clear as possible. Unnecessary repetitions, overly long sentences, or tangential explanations can increase the number of tokens needed.
Requesting Shorter Responses: In some cases, you can control the length of the responses generated by the model. Shorter responses mean fewer tokens.
Recalling Previous Messages: Depending on the application, it may be useful to enable or disable the function for recalling previous messages. This setting can be adjusted in ChatGPT-X under “Settings.” It is important to note that when this function is enabled, the texts of both previous questions and answers are added to the total number of tokens, always referring to the current chat.
Activating the Recall Function: For example, suppose you use ChatGPT for text summarization. You are not satisfied with the first summary and issue another command to improve the text. In this case, it would be sensible to activate the recall function. This way, the new command can build on the insights of the previous one, delivering an improved summary. This saves tokens, as you do not have to re-enter the initial text each time.
Deactivating the Recall Function: Suppose you use ChatGPT to generate a series of thematically unrelated poems. In this case, it would make sense to deactivate the recall function. This way, each new prompt for a poem is treated independently of the previous ones, leading to unique, independent poems. Alternatively, you can also start a new chat for each conversation to ensure that previous prompts do not influence the new ones. This saves tokens, as unnecessary texts unrelated to the new prompt are not counted.