En este artículo, exploramos qué son los tokens y cómo se calculan. Además, proporcionamos un ejemplo concreto de su uso y ofrecemos consejos para ahorrar fichas de forma eficiente.
- Definición de fichas
- Cómo se calculan las fichas
- Un ejemplo de fichas
- Comparación entre la tokenización de palabras y subpalabras
- Uso eficiente de fichas
Definición de fichas
Los tokens son un componente central en el procesamiento de texto de los modelos de aprendizaje automático como ChatGPT de OpenAI, ya que constituyen la base para comprender e interpretar los datos de texto. Estos elementos, también denominados tokens, son las unidades más pequeñas que pueden procesar dichos modelos.
En su forma más simple, un token puede representar una sola palabra, un signo de puntuación o un espacio. Sin embargo, los modelos más complejos, como ChatGPT, amplían este concepto y pueden definir los tokens como partes de una palabra o incluso varias palabras. Este enfoque se conoce como tokenización de subpalabras.
Cómo se calculan las fichas
Al procesar un texto, primero se descompone en una serie de tokens. Este proceso se denomina tokenización. A continuación, el modelo utiliza los valores numéricos representativos de estos tokens para analizar y predecir el texto.
Un aspecto importante es la limitación del número de tokens que puede procesar un modelo. Por ejemplo, con GPT-3.5 Turbo, este límite es de 4.096 tokens, y con GPT-4, de 8.192 tokens. Esta limitación se aplica tanto a los textos de entrada como a los de salida y también se denomina ventana de contexto. El número de tokens permitidos en un modelo de chat como ChatGPT no sólo depende de las limitaciones técnicas del propio modelo, sino que también puede ser fijado por el operador del chat o la aplicación específica.
Un ejemplo de fichas
Una frase como "ChatGPT es un modelo de lenguaje de OpenAI" se descompondría en tokens individuales. En una simple tokenización de palabras, esta frase podría dividirse en los siguientes tokens:
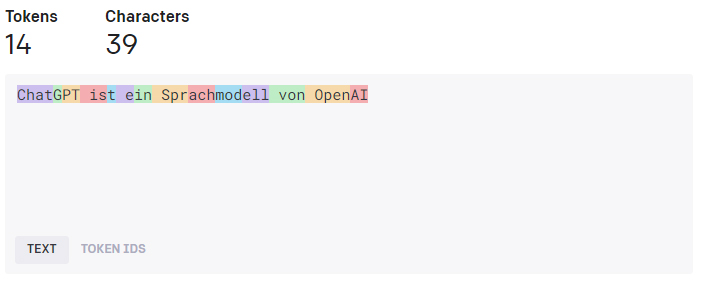
Sin embargo, en la tokenización de subpalabras, la misma frase podría descomponerse en más o menos tokens, dependiendo de la lógica de tokenización específica del modelo.
Comparación entre la tokenización de palabras y subpalabras
Supongamos que tenemos un texto de 1.000 palabras. En una tokenización simple por palabras, también tendríamos 1.000 tokens. Sin embargo, en la tokenización de subpalabras, el número de tokens podría variar. Una palabra como "configuración", por ejemplo, podría descomponerse en varios tokens como "Confi", "gura", "tión". Del mismo modo, un signo de puntuación o un espacio también podrían contarse como un token independiente. Esto significa que el número de tokens podría ser mayor que el número de palabras del texto.
Uso eficiente de fichas
En general, cuanto menos texto haya tanto en la pregunta como en la
respuesta, menos tokens se consumen. Este es un aspecto importante a tener en cuenta cuando se utilizan modelos como ChatGPT para maximizar la eficiencia y optimizar el uso de tokens.
Introducción de texto eficaz: Intenta que tu entrada sea lo más concisa y clara posible. Las repeticiones innecesarias, las frases demasiado largas o las explicaciones tangenciales pueden aumentar el número de tokens necesarios.
Solicitar respuestas más cortas: En algunos casos, puedes controlar la longitud de las respuestas generadas por el modelo. Las respuestas más cortas significan menos tokens.
Recuperar mensajes anteriores: Dependiendo de la aplicación, puede ser útil activar o desactivar la función para recuperar mensajes anteriores. Esta configuración puede ajustarse en ChatGPT-X en "Configuración". Es importante tener en cuenta que cuando esta función está activada, los textos de las preguntas y respuestas anteriores se añaden al número total de tokens, siempre referidos al chat actual.
Activación de la función de recuperación: Por ejemplo, suponga que utiliza ChatGPT para resumir un texto. No está satisfecho con el primer resumen y emite otro comando para mejorar el texto. En este caso, sería sensato activar la función de recuperación. De este modo, el nuevo comando puede basarse en los conocimientos del anterior y ofrecer un resumen mejorado. Así se ahorran fichas, ya que no hay que volver a introducir el texto inicial cada vez.
Desactivación de la función de recuperación: Supongamos que utiliza ChatGPT para generar una serie de poemas sin relación temática. En este caso, tendría sentido desactivar la función de recuperación. De esta forma, cada nueva pregunta para un poema se trata independientemente de las anteriores, dando lugar a poemas únicos e independientes. Alternativamente, también puedes iniciar un nuevo chat para cada conversación para asegurarte de que los mensajes anteriores no influyen en los nuevos. Esto ahorra tokens, ya que los textos innecesarios no relacionados con el nuevo tema no se tienen en cuenta.