Dans cet article, nous examinons ce que sont les jetons et comment ils sont calculés. En outre, nous donnons un exemple concret de leur utilisation et proposons des conseils pour économiser efficacement les jetons.
- Définition des jetons
- Comment les jetons sont-ils calculés ?
- Un exemple de jetons
- Comparaison entre la tokenisation des mots et des sous-mots
- Utilisation efficace des jetons
Définition des jetons
Les jetons sont un élément central du traitement du texte par les modèles d'apprentissage automatique tels que le ChatGPT d'OpenAI, car ils constituent la base de la compréhension et de l'interprétation des données textuelles. Ces éléments, également appelés "tokens", sont les plus petites unités que ces modèles peuvent traiter.
Dans sa forme la plus simple, un jeton peut représenter un seul mot, un signe de ponctuation ou un espace. Cependant, des modèles plus complexes comme ChatGPT étendent ce concept et peuvent définir les jetons comme des parties d'un mot ou même de plusieurs mots. Cette approche est connue sous le nom de tokénisation par sous-mots.
Comment les jetons sont-ils calculés ?
Lors du traitement d'un texte, celui-ci est d'abord décomposé en une série de jetons. Ce processus est appelé "tokenisation". Le modèle utilise ensuite les valeurs numériques représentatives de ces tokens pour analyser et prédire le texte.
Un aspect important est la limitation du nombre de jetons qu'un modèle peut traiter. Par exemple, avec GPT-3.5 Turbo, cette limite est de 4 096 tokens, et avec GPT-4, elle est de 8 192 tokens. Cette limite s'applique aux textes d'entrée et de sortie et est également appelée fenêtre contextuelle. Le nombre de jetons autorisé dans un modèle de chat tel que ChatGPT dépend non seulement des limitations techniques du modèle lui-même, mais peut également être fixé par l'opérateur du chat ou par l'application spécifique.
Un exemple de jetons
Une phrase comme "ChatGPT est un modèle de langage d'OpenAI" serait décomposée en jetons individuels. Dans une simple tokenisation de mots, cette phrase pourrait être décomposée dans les tokens suivants :
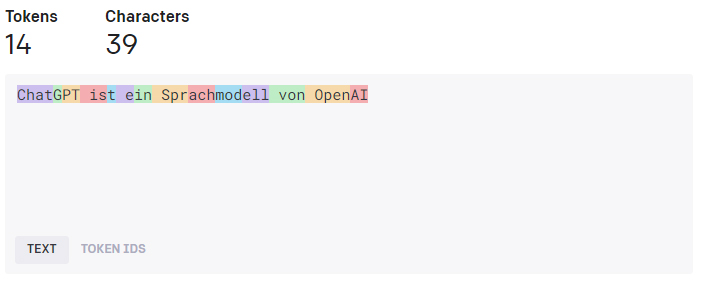
Cependant, dans la tokenisation des sous-mots, la même phrase peut être décomposée en plus ou moins de tokens, en fonction de la logique de tokenisation spécifique du modèle.
Comparaison entre la tokenisation des mots et des sous-mots
Supposons que nous ayons un texte de 1 000 mots. Dans le cas d'une simple tokenisation de mots, nous aurions également 1 000 tokens. Toutefois, dans le cas d'une tokénisation par sous-mots, le nombre de tokens peut varier. Un mot comme "configuration", par exemple, pourrait être décomposé en plusieurs jetons tels que "Confi", "gura", "tion". De même, un signe de ponctuation ou un espace peut également être compté comme un jeton distinct. Cela signifie que le nombre de jetons peut être supérieur au nombre de mots dans le texte.
Utilisation efficace des jetons
En général, moins il y a de texte dans la question et la réponse, moins il y a de tokens consommés.
moins de jetons sont consommés. Il s'agit d'un aspect important à garder à l'esprit lorsque l'on utilise des modèles comme ChatGPT pour maximiser l'efficacité et optimiser l'utilisation des jetons.
Saisie efficace du texte : Essayez d'être aussi concis et clair que possible. Les répétitions inutiles, les phrases trop longues ou les explications tangentielles peuvent augmenter le nombre de jetons nécessaires.
Demander des réponses plus courtes : Dans certains cas, vous pouvez contrôler la longueur des réponses générées par le modèle. Des réponses plus courtes signifient moins de jetons.
Rappel des messages précédents : Selon l'application, il peut être utile d'activer ou de désactiver la fonction de rappel des messages précédents. Ce paramètre peut être ajusté dans ChatGPT-X sous "Paramètres". Il est important de noter que lorsque cette fonction est activée, les textes des questions et des réponses précédentes sont ajoutés au nombre total de jetons, se référant toujours au chat actuel.
Activation de la fonction de rappel : Supposons par exemple que vous utilisiez ChatGPT pour résumer un texte. Vous n'êtes pas satisfait du premier résumé et vous lancez une autre commande pour améliorer le texte. Dans ce cas, il serait judicieux d'activer la fonction de rappel. De cette manière, la nouvelle commande peut s'appuyer sur les connaissances acquises lors de la précédente et fournir un résumé amélioré. Cela permet d'économiser des jetons, car il n'est pas nécessaire de réintroduire le texte initial à chaque fois.
Désactivation de la fonction de rappel : Supposons que vous utilisiez ChatGPT pour générer une série de poèmes sans rapport thématique. Dans ce cas, il serait judicieux de désactiver la fonction de rappel. De cette manière, chaque nouvelle proposition de poème est traitée indépendamment des précédentes, ce qui permet de créer des poèmes uniques et indépendants. Vous pouvez également lancer un nouveau chat pour chaque conversation afin de vous assurer que les messages précédents n'influencent pas les nouveaux. Cela permet d'économiser des jetons, car les textes inutiles sans rapport avec la nouvelle invite ne sont pas comptabilisés.